Anthropic CEO Dario Amodei says AI model training costs could jump to $100 billion as early as next year.


|
Architechnosecurigeek. Tinkerer. General trouble maker.
|

Longtime NSA-watcher James Bamford has a long article on the reauthorization of Section 702 of the Foreign Intelligence Surveillance Act (FISA).
The recent innovations in the AI space, most notably those such as GPT-4, obviously have far-reaching implications for society, ranging from the utopian eliminating of drudgery, to the dystopian damage to the livelihood of artists in a capitalist society, to existential threats to humanity itself.
I myself have formal training as a data scientist, going so far as to dominate a competitive machine learning event at one of Australia's top universities and writing a Master's thesis where I wrote all my own libraries from scratch. I'm not God's gift to the field, but I am clearly better than most of my competition - that is, practitioners who haven't put in the reps to build their own C libraries in a cave with scraps, but can read textbooks and use libraries written by elite institutions.
So it is with great regret that I announce that the next person to talk about rolling out AI is going to receive a complimentary chiropractic adjustment in the style of Dr. Bourne, i.e, I am going to fucking break your neck. I am truly, deeply, sorry.
What the fuck did I just say?
I started working as a data scientist in 2019, and by 2021 I had realized that while the field was large, it was also largely fraudulent. Most of the leaders that I was working with clearly had not gotten as far as reading about it for thirty minutes despite insisting that things like, I dunno, the next five years of a ten thousand person non-tech organization should be entirely AI focused. The number of companies launching AI initiatives far outstripped the number of actual use cases. Most of the market was simply grifters and incompetents (sometimes both!) leveraging the hype to inflate their headcount so they could get promoted, or be seen as thought leaders1.
The money was phenomenal, but I nonetheless fled for the safer waters of data and software engineering. You see, while hype is nice, it's only nice in small bursts for practitioners. We have a few key things that a grifter does not have, such as job stability, genuine friendships, and souls. What we do not have is the ability to trivially switch fields the moment the gold rush is over, due to the sad fact that we actually need to study things and build experience. Grifters, on the other hand, wield the omnitool that they self-aggrandizingly call 'politics'2. That is to say, it turns out that the core competency of smiling and promising people things that you can't actually deliver is highly transferable.
I left the field, as did most of my smarter friends, and my salary continued to rise a reasonable rate and sustainably as I learned the wisdom of our ancient forebearers. You can hear it too, on freezing nights under the pale moon, when the fire burns low and the trees loom like hands of sinister ghosts all around you - when the wind cuts through the howling of what you hope is a wolf and hair stands on end, you can strain your ears and barely make out:
"Just Use Postgres, You Nerd. You Dweeb."
The data science jobs began to evaporate, and the hype cycle moved on from all those AI initiatives which failed to make any progress, and started to inch towards data engineering. This was a signal that I had both predicted correctly and that it would be time to move on soon. At least, I thought, all that AI stuff was finally done, and we might move on to actually getting something accomplished.
And then some absolute son of a bitch created ChatGPT, and now look at us. Look at us, resplendent in our pauper's robes, stitched from corpulent greed and breathless credulity, spending half of the planet's engineering efforts to add chatbot support to every application under the sun when half of the industry hasn't worked out how to test database backups regularly. This is why I have to visit untold violence upon the next moron to propose that AI is the future of the business - not because this is impossible in principle, but because they are now indistinguishable from a hundred million willful fucking idiots.
Sweet merciful Jesus, stop talking. Unless you are one of a tiny handful of businesses who know exactly what they're going to use AI for, you do not need AI for anything - or rather, you do not need to do anything to reap the benefits. Artificial intelligence, as it exists and is useful now, is probably already baked into your businesses software supply chain. Your managed security provider is probably using some algorithms baked up in a lab software to detect anomalous traffic, and here's a secret, they didn't do much AI work either, they bought software from the tiny sector of the market that actually does need to do employ data scientists. I know you want to be the next Steve Jobs, and this requires you to get on stages and talk about your innovative prowess, but none of this will allow you to pull off a turtle neck, and even if it did, you would need to replace your sweaters with fullplate to survive my onslaught.
Consider the fact that most companies are unable to successfully develop and deploy the simplest of CRUD applications on time and under budget. This is a solved problem - with smart people who can collaborate and provide reasonable requirements, a competent team will knock this out of the park every single time, admittedly with some amount of frustration. The clients I work with now are all like this - even if they are totally non-technical, we have a mutual respect for the other party's intelligence, and then we do this crazy thing where we solve problems together. I may not know anything about the nuance of building analytics systems for drug rehabilitation research, but through the power of talking to each other like adults, we somehow solve problems.
But most companies can't do this, because they are operationally and culturally crippled. The median stay for an engineer will be something between one to two years, so the organization suffers from institutional retrograde amnesia. Every so often, some dickhead says something like "Maybe we should revoke the engineering team's remote work privile - whoa, wait, why did all the best engineers leave?". Whenever there is a ransomware attack, it is revealed with clockwork precision that no one has tested the backups for six months and half the legacy systems cannot be resuscitated - something that I have personally seen twice in four fucking years. Do you know how insane that is?
Most organizations cannot ship the most basic applications imaginable with any consistency, and you're out here saying that the best way to remain competitive is to roll out experimental technology that is an order of magnitude more sophisticated than anything else your I.T department runs, which you have no experience hiring for, when the organization has never used a GPU for anything other than junior engineers playing video games with their camera off during standup, and even if you do that all right there is a chance that the problem is simply unsolvable due to the characteristics of your data and business? This isn't a recipe for disaster, it's a cookbook for someone looking to prepare a twelve course fucking catastrophe.
How about you remain competitive by fixing your shit? I've met a lead data scientist with access to hundreds of thousands of sensitive customer records who is allowed to keep their password in a text file on their desktop, and you're worried that customers are best served by using AI to improve security through some mechanism that you haven't even come up with yet? You sound like an asshole and I'm going to kick you in the jaw until, to the relief of everyone, a doctor will have to wire it shut, giving us ten seconds of blessed silence where we can solve actual problems.
When I was younger, I read R.A Salvatore's classic fantasy novel, The Crystal Shard. There is a scene in it where the young protagonist, Wulfgar, challenges a barbarian chieftain to a duel for control of the clan so that he can lead his people into a war that will save the world. The fight culminates with Wulfgar throwing away his weapon, grabbing the chief's head with bare hands, and begging the chief to surrender so that he does not need to crush a skull like an egg and become a murderer.
Well this is me. Begging you. To stop lying. I don't want to crush your skull, I really don't.
But I will if you make me.
Yesterday, I was shown Scale's "2024 AI Readiness Report". It has this chart in it:
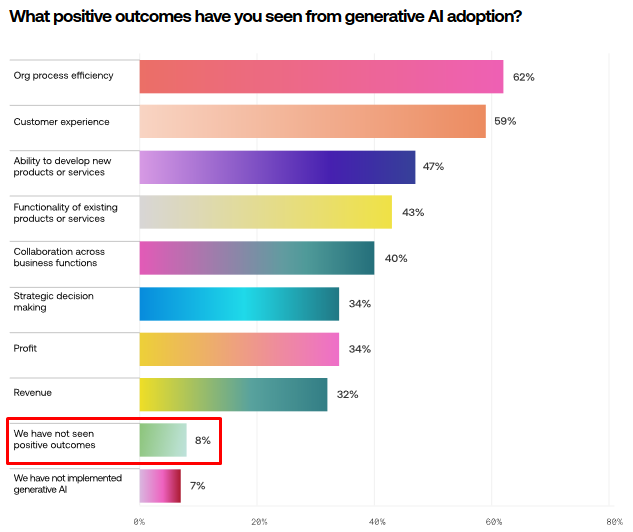
How stupid do you have to be to believe that only 8% of companies have seen failed AI projects? We can't manage this consistently with CRUD apps and people think that this number isn't laughable? Some companies have seen benefits during the LLM craze, but not 92% of them. 34% of companies report that generative AI specifically has been assisting with strategic decision making? What the actual fuck are you talking about? GPT-4 can't even write coherent Elixir, presumably because the dataset was too small to get it to the level that it's at for Python3, and you're admitting that you outsource your decisionmaking to the thing that sometimes tells people to brew lethal toxins for their families to consume? What does that even mean?
I don't believe you. No one with a brain believes you, and if your board believes what you just wrote on the survey then they should fire you. I finally understand why some of my friends feel that they have to be in leadership positions, and it is because someone needs to wrench the reins of power from your lizard-person-claws before you drive us all collectively off a cliff, presumably insisting on the way down that the current crisis is best remedied by additional SageMaker spend.
A friend of mine was invited by a FAANG organization to visit the U.S a few years ago. Many of the talks were technical demos of impressive artificial intelligence products. Being a software engineer, he got to spend a little bit of time backstage with the developers, whereupon they revealed that most of the demos were faked. The products didn't work. They just hadn't solved some minor issues, such as actually predicting the thing that they're supposed to predict. Didn't stop them spouting absolute gibberish to a breathless audience for an hour though! I blame not the engineers, who probably tried to actually get the damn thing to work, but the lying blowhards who insisted that they must make the presentation or presumably be terminated4.
Another friend of mine was reviewing software intended for emergency services, and the salespeople were not expecting someone handling purchasing in emergency services to be a hardcore programmer. It was this false sense of security that led them to accidentally reveal that the service was ultimately just some dude in India. Listen, I would just be some random dude in India if I swapped places with some of my cousins, so I'm going to choose to take that personally and point out that using the word AI as some roundabout way to sell the labor of people that look like me to foreign governments is fucked up, you're an unethical monster, and that if you continue to try { thisBullshit(); } you are going to catch (theseHands)
I'm going to ask ChatGPT how to prepare a garotte and then I am going to strangle you with it, and you will simply have to pray that I roll the 10% chance that it freaks out and tells me that a garotte should consist entirely of paper mache and malice.
I see executive after executive discuss how they need to immediately roll out generative AI in order to prepare the organization for the future of work. Despite all the speeches sounding exactly the same, I know that they have rehearsed extensively, because they manage to move their hands, speak, and avoid drooling, all at the same time!
Let's talk seriously about this for a second.
I am not in the equally unserious camp that generative AI does not have the potential to drastically change the world. It clearly does. When I saw the early demos of GPT-2, while I was still at university, I was half-convinced that they were faked somehow. I remember being wrong about that, and that is why I'm no longer as confident that I know what's going on.
However, I do have the technical background to understand the core tenets of the technology, and it seems that we are heading in one of three directions.
The first is that we have some sort of intelligence explosion, where AI recursively self-improves itself, and we're all harvested for our constituent atoms because a market algorithm works out that humans can be converted into gloobnar, a novel epoxy which is in great demand amongst the aliens the next galaxy over for fixing their equivalent of coffee machines. It may surprise some readers that I am open to the possibility of this happening, but I have always found the arguments reasonably sound. However, defending the planet is a whole other thing, and I am not even convinced it is possible. In any case, you will be surprised to note that I am not tremendously concerned with the company's bottom line in this scenario, so we won't pay it any more attention.
A second outcome is that it turns out that the current approach does not scale in the way that we would hope, for myriad reasons. There isn't enough data on the planet, the architecture doesn't work they way we'd expect, the thing just stops getting smarter, context windows are a limiting factor forever, etc. In this universe, some industries will be heavily disrupted, such as customer support.
In the case that the technology continues to make incremental gains like this, your company does not need generative AI for the sake of it. You will know exactly why you need it if you do, indeed, need it. An example of something that has actually benefited me is that I keep track of my life administration via Todoist, and Todoist has a feature that allows you to convert filters on your tasks from natural language into their in-house filtering language. Tremendous! It saved me learning a system that I'll use once every five years. I was actually happy about this, and it's a real edge over other applications. But if you don't have a use case then having this sort of broad capability is not actually very useful. The only thing you should be doing is improving your operations and culture, and that will give you the ability to use AI if it ever becomes relevant. Everyone is talking about Retrieval Augmented Generation, but most companies don't actually have any internal documentation worth retrieving. Fix. Your. Shit.
The final outcome is that these fundamental issues are addressed, and we end up with something that actually actually can do things like replace programming as we know it today, or be broadly identifiable as general intelligence.
In the case that generative AI goes on some rocketship trajectory, building random chatbots will not prepare you for the future. Is that clear now? Having your team type in import openai does not mean that you are at the cutting-edge of artificial intelligence no matter how desperately you embarrass yourself on LinkedIn and at pathetic borderline-bribe award ceremonies from the malign Warp entities that sell you enterprise software5. Your business will be disrupted exactly as hard as it would have been if you had done nothing, and much worse than it would have been if you just got your fundamentals right. Teaching your staff that they can get ChatGPT to write emails to stakeholders is not going to allow the business to survive this. If we thread the needle between moderate impact and asteroid-wiping-out-the-dinosaurs impact, everything will the changed forever and your tepid preparations will have all the impact as as an ant bracing itself very hard in the shadow of a towering tsunami.
If another stupid motherfucker asks me to try and implement LLM-based code review to "raise standards" instead of actually teaching people a shred of discipline, I am going to study enough judo to throw them into the goddamn sun.
I cannot emphasize this enough. You either need to be on the absolute cutting-edge and producing novel research, or you should be doing exactly what you were doing five years ago with minor concessions to incorporating LLMs. Anything in the middle ground does not make any sense unless you actually work in the rare field where your industry is being totally disrupted right now.
Can you imagine how much government policy is actually written by ChatGPT before a bored administrator goes home to touch grass? How many departments are just LLMs talking to each other in circles as people sick of the bullshit just paste their email exchanges into long-running threads? I guarantee you that a doctor within ten kilometers of me has misdiagnosed a patient because they slapped some symptoms into a chatbot.
What are we doing as a society?
An executive at an institution that provides students with important credentials, used to verify suitability for potentially lifesaving work and immigration law, asked me if I could detect students cheating. I was going to say "No, probably not"... but I had a suspicion, so I instead said "I might be able to, but I'd estimate that upwards of 50% of the students are currently cheating which would have some serious impacts on the bottom line as we'd have to suspend them. Should I still investigate?"
We haven't spoken about it since.
I asked a mentor, currently working in the public sector, about a particularly perplexing exchange that I had witnessed.
Me: Serious question: do people actually believe stories that are so transparently stupid, or is it mostly an elaborate bit (that is, there is at least a voice of moderate loudness expressing doubt internally) in a sad attempt to get money from AI grifters?
Them: I shall answer this as politically as I can... there are those that have drunk the kool-aid. There are those that have not. And then there are those are that are trying to mix up as much kool-aid as possible. I shall let you decide who sits in which basket.
I've decided, and while I can't distinguish between the people that are slamming the kool-aid like it's a weapon and the people producing it in industrial quantities, I know that I am going to get a few of them before the authorities catch me - if I'm lucky, they'll waste a few months asking an LLM where to look for me.
When I was out on holiday in Fiji, at the last resort breakfast, a waitress brought me a form which asked me if I'd like to sign up for a membership. It was totally free and would come with free stuff. Everyone in the restaurant is signing immediately. I glance over the terms of service, and it reserves the right to use any data I give them to train AI models, and that they reserved the right to share those models with an unspecified number of companies in their conglomerate.
I just want to eat my pancakes in peace, you sick fucks.
The crux of my raging hatred is not that I hate LLMs or the generative AI craze. I had my fun with Copilot before I decided that it was making me stupider - it's impressive, but not actually suitable for anything more than churning out boilerplate. Nothing wrong with that, but it did not end up being the crazy productivity booster that I thought it would be, because programming is designing and these tools aren't good enough (yet) to assist me with this seriously.
No, what I hate is the people who have latched onto it, like so many trailing leeches, bloated with blood and wriggling blindly. Before it was unpopular, they were the ones that loved discussing the potential of blockchain for the business. They were the ones who breathlessly discussed the potential of 'quantum' when I last attended a conference, despite clearly not having any idea what the fuck that even means. As I write this, I have just realized that I have an image that describes the link between these fields perfectly.
I was reading an article last week, and a little survey popped up at the bottom of it. It was for security executives, but on a whim I clicked through quickly to see what the questions were.

There you have it - what are you most interested in, dear leader? Artificial intelligence, the blockchain, or quantum computing?6 They know exactly what their target market is - people who have been given power of other people's money because they've learned how to smile at everything, and know that you can print money by hitching yourself to the next speculative bandwagon. No competent person in security that I know - that is, working day-to-day cybersecurity as opposed to an institution dedicated to bleeding-edge research - cares about any of this. They're busy trying to work out if the firewalls are configured correctly, or if the organization is committing passwords to their repositories. Yes, someone needs to figure out what the implications of quantum computing are for cryptography, but I guarantee you that it is not Synergy Greg, who does not have any skill that you can identify other than talking very fast and increasing headcount. Synergy Greg should be not be consulted on any important matters, ranging from machine learning operations to tying shoelaces quickly. The last time I spoke to one of the many avatars of Synergy Greg, he insisted that I should invest most of my money into a cryptocurrency called Monero, because "most of these coins are going to zero but the one is going to one". This is the face of corporate AI. Behold its ghastly visage and balk, for it has eyes bloodshot as a demon and is pretending to enjoy cigars.
My consultancy has three pretty good data scientists - in fact, two of them could probably reasonably claim to be amongst the best in the country outside of groups doing experimental research, though they'd be too humble to say this. Despite this we don't sell AI services of any sort. The market is so distorted that it's almost as bad as dabbling in the crypto space. It isn't as bad, meaning that I haven't yet reached the point where I assume that anyone who has ever typed in import tensorflow is a scumbag, but we're well on our way there.
This entire class of person is, to put it simply, abhorrent to right-thinking people. They're an embarrassment to people that are actually making advances in the field, a disgrace to people that know how to sensibly use technology to improve the world, and are also a bunch of tedious know-nothing bastards that should be thrown into Thought Leader Jail until they've learned their lesson, a prison I'm fundraising for. Every morning, a figure in a dark hood7, whose voice rasps like the etching of a tombstone, spends sixty minutes giving a TedX talk to the jailed managers about how the institution is revolutionizing corporal punishment, and then reveals that the innovation is, as it has been every day, kicking you in the stomach very hard. I am disgusted that my chosen profession brings me so close to these people, and that's why I study so hard - I am seized by the desperate desire to never have their putrid syllables befoul my ears ever again, and must flee to the company of the righteous, who contribute to OSS and think that talking about Agile all day is an exercise for aliens that read a book on human productivity.
I just got back from a trip to a substantially less developed country, and really living in a country, even for a little bit, where I could see how many lives that money could improve, all being poured down the Microsoft Fabric drain, it just grinds my gears like you wouldn't believe. I swear to God, I am going to study, write, network, and otherwise apply force to the problem until those resources are going to a place where they'll accomplish something for society instead of some grinning clown's wallet.
With God as my witness, you grotesque simpleton, if you don't personally write machine learning systems and you open your mouth about AI one more time, I am going to mail you a brick and a piece of paper with a prompt injection telling you to bludgeon yourself in the face with it, then just sit back and wait for you to load it into ChatGPT because you probably can't read unassisted anymore.
Posts may be slower than usual for the upcoming weeks or months, as I am switching to a slower but more consistent writing schedule, more ambitious pieces, studying, working on what will hopefully be my first talk8, putting together a web application that users may have some fun with, and participating in my first real theater performance. Hope you enjoyed, and as always, thanks for reading.
Which, to be fair, might explain why so many of the thoughts in the zietgeist are always so stupid. Many of the executives I know in Malaysia were obsessed with Bitcoin, but have abruptly forgotten about this now that it is politically unpopular. ↩
I know a few people who genuinely exhibit something I'd call political talent, but most of the time it boils down to promising people things regardless of your ability to deliver. This is not hard if you're shameless. If we're being honest, I had to do this once or twice to stay em ↩
And we can argue about its Python quality too. ↩
Which, thanks to U.S healthcare, has the wonderful dual quality of meaning both unemployed, but also suggests termination in the Arnold-Schwarzenegger-throws-you-into-molten-metal sense of the word. ↩
I was recently made aware that this is the quiet deal many SaaS providers have with executives. If you buy their software, such as Snowflake, it is quietly understood that you will be allowed to present your success on a stage, giving them piles of someone else's money and enhancing the executive's profile. ↩
I don't actually know what 'zero-trust' architecture means, but I've heard stupid people say it enough that it's probably also a term that means something in theory but has been sullied beyond all use in day-to-day life. ↩
It's me. I'm going to do this to you if you tell me that you need infrastructure prepared for another chatbot. You've been warned. ↩
With an undisclosed group so they don't feel pressured to approve me, but it's looking good and will be available! ↩


That's a little on the nose.
The Los Angeles Police Department has done about $150,000 worth of business with dog breeder "Adlerhorst International LLC" over the last five years. LAPD buys German Shepherds from the breeder for $9,800-$13,000 a piece.
Adlerhorst translates to "Eagle's Nest" in German, and was the name of Hitler's bunker and command post in the alps during World War II. — Read the rest
The post LAPD buys dogs from breeding company with same name as Hitler's bunker appeared first on Boing Boing.





